基本介绍
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景
关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库
对比
| Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
Sharding-JDBC的优势在于对Java应用的友好度
内部结构
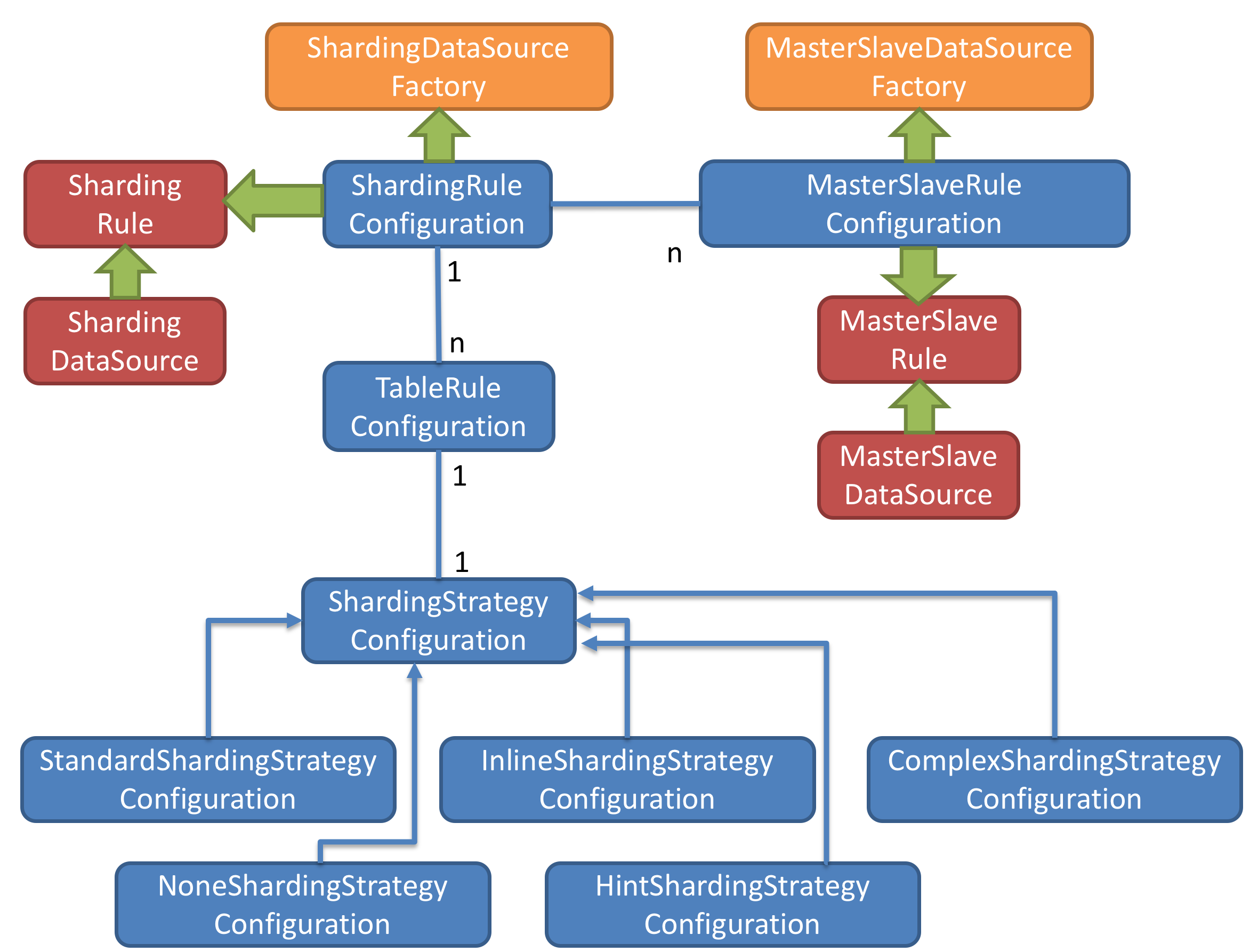
-
黄色部分
图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有ShardingDataSourceFactory和MasterSlaveDataSourceFactory两个工厂类。ShardingDataSourceFactory用于创建分库分表或分库分表+读写分离的JDBC驱动,MasterSlaveDataSourceFactory用于创建独立使用读写分离的JDBC驱动
-
蓝色部分
图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多变的配置方式。 ShardingRuleConfiguration是分库分表配置的核心和入口,它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。每一组相同规则分片的表配置一个TableRuleConfiguration。如果需要分库分表和读写分离共同使用,每一个读写分离的逻辑库配置一个MasterSlaveRuleConfiguration。 每个TableRuleConfiguration对应一个ShardingStrategyConfiguration,它有5中实现类可供选择
仅读写分离使用MasterSlaveRuleConfiguration即可
-
红色部分
图中红色部分表示的是内部对象,由Sharding-JDBC内部使用,应用开发者无需关注。Sharding-JDBC通过ShardingRuleConfiguration和MasterSlaveRuleConfiguration生成真正供ShardingDataSource和MasterSlaveDataSource使用的规则对象。ShardingDataSource和MasterSlaveDataSource实现了DataSource接口,是JDBC的完整实现方案
-
初始化流程
- 配置Configuration对象
- 通过Factory对象将Configuration对象转化为Rule对象
- 通过Factory对象将Rule对象与DataSource对象装配
- Sharding-JDBC使用DataSource对象进行分库
功能列表
数据源配置
# 真实数据源名称,多个数据源用逗号区分
spring.shardingsphere.datasource.names=
# <actual-data-source-name> 表示真实数据源名称
# 数据库连接池全类名
spring.shardingsphere.datasource.<actual-data-source-name>.type=
# 数据库驱动类名,以数据库连接池自身配置为准
spring.shardingsphere.datasource.<actual-data-source-name>.driver-class-name=
# 数据库 URL 连接,以数据库连接池自身配置为准
spring.shardingsphere.datasource.<actual-data-source-name>.jdbc-url=
# 数据库用户名,以数据库连接池自身配置为准
spring.shardingsphere.datasource.<actual-data-source-name>.username=
# 数据库密码,以数据库连接池自身配置为准
spring.shardingsphere.datasource.<actual-data-source-name>.password=
# ... 数据库连接池的其它属性
spring.shardingsphere.datasource.<actual-data-source-name>.<xxx>=
数据分片
介绍
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案
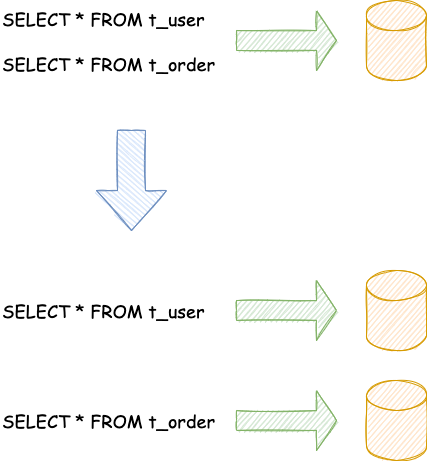
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示
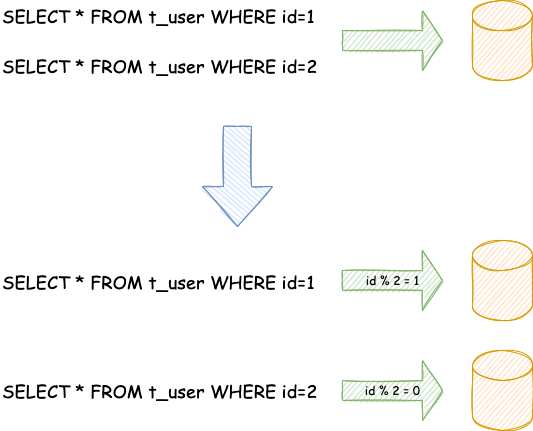
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案
数据分片产生的问题
- 面对如此散乱的分片之后的数据,应用开发工程师和数据库管理员对数据库的操作变得异常繁重就是其中的重要挑战之一。 他们需要知道数据需要从哪个具体的数据库的子表中获取
- 能够正确的运行在单节点数据库中的 SQL,在分片之后的数据库中并不一定能够正确运行。 例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理
- 跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。 在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务
数据分片配置
# 标准分片表配置
spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式
# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-algorithm-name= # 分片算法名称
# 用于多分片键的复合分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-columns= # 分片列名称,多个列以逗号分隔
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-algorithm-name= # 分片算法名称
# 用于 Hint 的分片策略
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.hint.sharding-algorithm-name= # 分片算法名称
# 分表策略,同分库策略
spring.shardingsphere.rules.sharding.tables.<table-name>.table-strategy.xxx= # 省略
# 自动分片表配置
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.actual-data-sources= # 数据源名
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-algorithm-name= # 自动分片算法名称
# 分布式序列策略配置
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.column= # 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.key-generator-name= # 分布式序列算法名称
spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[1]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[0]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[1]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[x]= # 广播表规则列表
spring.shardingsphere.sharding.default-database-strategy.xxx= # 默认数据库分片策略
spring.shardingsphere.sharding.default-table-strategy.xxx= # 默认表分片策略
spring.shardingsphere.sharding.default-key-generate-strategy.xxx= # 默认分布式序列策略
spring.shardingsphere.sharding.default-sharding-column= # 默认分片列名称
# 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.type= # 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.props.xxx= # 分片算法属性配置
# 分布式序列算法配置
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.type= # 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.props.xxx= # 分布式序列算法属性配置
读写分离
介绍
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库
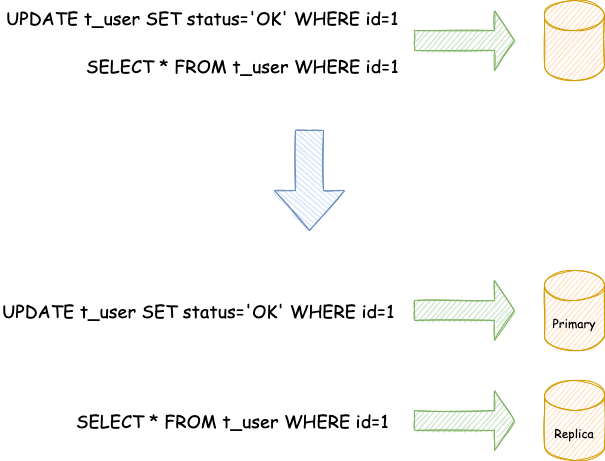
读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能
读写分离产生的问题
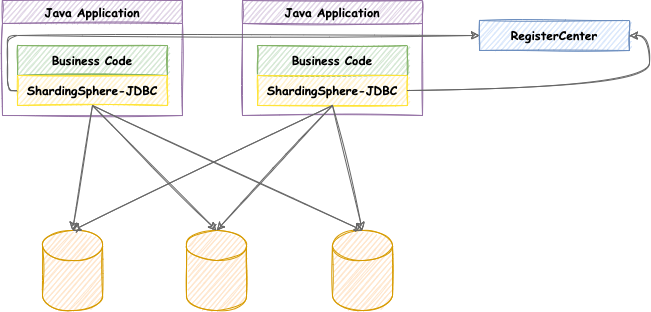
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。 这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。 下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系

读写分离配置
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.type= # 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.auto-aware-data-source-name= # 自动发现数据源名称(与数据库发现配合使用)
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.write-data-source-name= # 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.read-data-source-names= # 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.load-balancer-name= # 负载均衡算法名称
# 负载均衡算法配置
spring.shardingsphere.rules.readwrite-splitting.load-balancers.<load-balance-algorithm-name>.type= # 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.<load-balance-algorithm-name>.props.xxx= # 负载均衡算法属性配置
项目使用
导入依赖
<!--数据库连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<!--数据库连接驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--sharding-jdbc依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--mybatis-plus依赖,用于简化代码-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
创建数据源
CREATE DATABASE sharding1
use sharding1
DROP TABLE IF EXISTS `test1`;
CREATE TABLE `test1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1508619855433437186 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1508620586928492547 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ------------------------------------------------------------
CREATE DATABASE sharding2
use sharding2
DROP TABLE IF EXISTS `test2`;
CREATE TABLE `test2` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1508619855433437186 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1508620586928492547 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
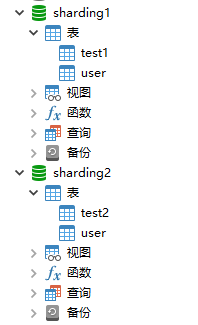
编写配置文件
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://101.43.76.201:3306/sharding1
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://101.43.76.201:3306/sharding2
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=
#指定数据库分布情况
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user
spring.shardingsphere.sharding.tables.test1.actual-data-nodes=ds$->{0}.test1
spring.shardingsphere.sharding.tables.test2.actual-data-nodes=ds$->{1}.test2
#指定表的主键策略
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#指定表的分片策略
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=sharding$->{id % 2 + 1}.user
#指定单个表的分库策略
spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=ds$->{id % 2}
#指定默认的分库策略
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id % 2}
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true
编写实体类和Mapper
实体类(使用lombok进行简化):
package com.xxy.sharding.pojo;
import lombok.Data;
@Data
public class User {
Long id;
String username;
String password;
}
Mapper(使用mybatis-plus进行简化):
package com.xxy.sharding.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.xxy.sharding.pojo.User;
import org.springframework.stereotype.Repository;
@Repository
public interface UserMapper extends BaseMapper<User> {
}
进行测试
package com.xxy.sharding;
import com.xxy.sharding.mapper.Test1Mapper;
import com.xxy.sharding.mapper.Test2Mapper;
import com.xxy.sharding.mapper.UserMapper;
import com.xxy.sharding.pojo.Test1;
import com.xxy.sharding.pojo.Test2;
import com.xxy.sharding.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.transaction.annotation.Transactional;
@SpringBootTest
class ShardingApplicationTests {
@Autowired
UserMapper userMapper;
@Autowired
Test1Mapper test1Mapper;
@Autowired
Test2Mapper test2Mapper;
@Test
@Transactional
void contextLoads() {
// 测试水平分库添加
userMapper.insert(new User());
// 测试水平分库查询
System.out.println(userMapper.selectList(null));
// 测试垂直分库添加
test1Mapper.insert(new Test1());
test2Mapper.insert(new Test2());
// 测试垂直分库查询
System.out.println(test1Mapper.selectList(null));
System.out.println(test2Mapper.selectList(null));
}
}
查看结果
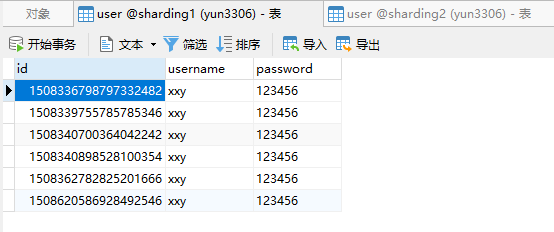
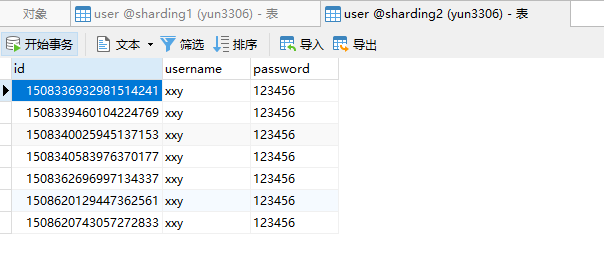
从数据库中的结果,可以看到,所有id为偶数的都添加至sharding1数据库中,而id为奇数的都添加至sharding2数据库中,故成功进行了分库分表操作
